

Ultimate 12 months I wrote about 8 databases that improve in-database mechanical device studying. In-database mechanical device studying is necessary as it brings the mechanical device studying processing to the information, which is a lot more environment friendly for large knowledge, quite than forcing knowledge scientists to extract subsets of the information to the place the mechanical device studying coaching and inference run.
Those databases every paintings otherwise:
- Amazon Redshift ML makes use of SageMaker Autopilot to robotically create prediction fashions from the information you specify by way of a SQL remark, which is extracted to an Amazon S3 bucket. The most productive prediction serve as discovered is registered within the Redshift cluster.
- BlazingSQL can run GPU-accelerated queries on knowledge lakes in Amazon S3, go the ensuing DataFrames to RAPIDS cuDF for knowledge manipulation, and in the end carry out mechanical device studying with RAPIDS XGBoost and cuML, and deep studying with PyTorch and TensorFlow.
- BigQuery ML brings a lot of the ability of Google Cloud Device Studying into the BigQuery knowledge warehouse with SQL syntax, with out extracting the information from the information warehouse.
- IBM Db2 Warehouse features a large set of in-database SQL analytics that incorporates some elementary mechanical device studying capability, plus in-database improve for R and Python.
- Kinetica supplies a complete in-database lifecycle answer for mechanical device studying sped up by way of GPUs, and will calculate options from streaming knowledge.
- Microsoft SQL Server can teach and infer mechanical device studying fashions in more than one programming languages.
- Oracle Cloud Infrastructure can host knowledge science assets built-in with its knowledge warehouse, object retailer, and purposes, making an allowance for a complete type construction lifecycle.
- Vertica has a pleasing set of mechanical device studying algorithms integrated, and will import TensorFlow and PMML fashions. It may possibly do prediction from imported fashions in addition to its personal fashions.
Now there’s every other database that may run mechanical device studying internally: Snowflake.
Contents
Snowflake assessment
Snowflake is a completely relational ANSI SQL undertaking knowledge warehouse that used to be constructed from the bottom up for the cloud. Its structure separates compute from garage as a way to scale up and down at the fly, immediately or disruption, even whilst queries are working. You get the efficiency you want precisely when you want it, and also you solely pay for the compute you employ.
Snowflake these days runs on Amazon Internet Services and products, Microsoft Azure, and Google Cloud Platform. It has lately added Exterior Tables On-Premises Garage, which we could Snowflake customers get entry to their knowledge in on-premises garage programs from corporations together with Dell Applied sciences and Natural Garage, increasing Snowflake past its cloud-only roots.
Snowflake is a completely columnar database with vectorized execution, making it in a position to addressing even essentially the most not easy analytic workloads. Snowflake’s adaptive optimization guarantees that queries robotically get the most efficient efficiency conceivable, with out a indexes, distribution keys, or tuning parameters to control.
Snowflake can improve limitless concurrency with its distinctive multi-cluster, shared knowledge structure. This permits more than one compute clusters to function concurrently at the identical knowledge with out degrading efficiency. Snowflake will also scale robotically to deal with various concurrency calls for with its multi-cluster digital warehouse function, transparently including compute assets all through height load sessions and cutting down when rather a lot subside.
Snowpark assessment
After I reviewed Snowflake in 2019, for those who sought after to program towards its API you had to run this system out of doors of Snowflake and fasten thru ODBC or JDBC drivers or thru local connectors for programming languages. That modified with the advent of Snowpark in 2021.
Snowpark brings to Snowflake deeply built-in, DataFrame-style programming within the languages builders like to make use of, beginning with Scala, then extending to Java and now Python. Snowpark is designed to make construction complicated knowledge pipelines a breeze and to permit builders to have interaction with Snowflake at once with out transferring knowledge.
The Snowpark library supplies an intuitive API for querying and processing knowledge in an information pipeline. The usage of this library, you’ll construct packages that procedure knowledge in Snowflake with out transferring knowledge to the machine the place your utility code runs.
The Snowpark API supplies programming language constructs for construction SQL statements. For instance, the API supplies a make a selection approach that you’ll use to specify the column names to go back, quite than writing 'make a selection column_name' as a string. Even supposing you’ll nonetheless use a string to specify the SQL remark to execute, you take pleasure in options like clever code finishing touch and kind checking whilst you use the local language constructs supplied by way of Snowpark.
Snowpark operations are accomplished lazily at the server, which reduces the volume of information transferred between your shopper and the Snowflake database. The core abstraction in Snowpark is the DataFrame, which represents a suite of information and gives learn how to function on that knowledge. For your shopper code, you assemble a DataFrame object and set it as much as retrieve the information that you need to make use of.
The knowledge isn’t retrieved on the time whilst you assemble the DataFrame object. As an alternative, when you’re in a position to retrieve the information, you’ll carry out an motion that evaluates the DataFrame gadgets and sends the corresponding SQL statements to the Snowflake database for execution.
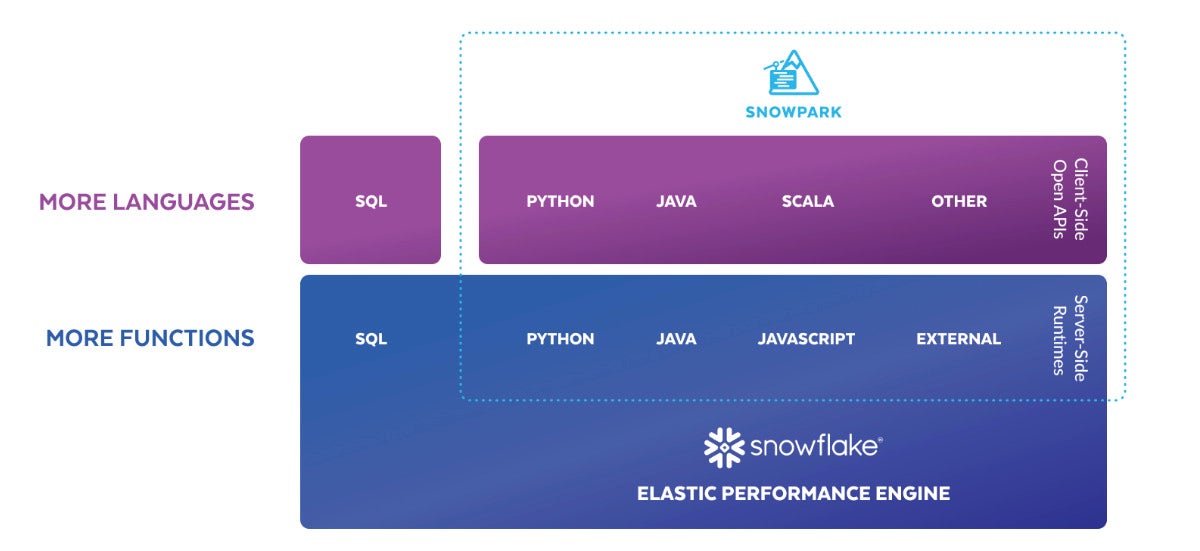 IDG
IDGSnowpark block diagram. Snowpark expands the inner programmability of the Snowflake cloud knowledge warehouse from SQL to Python, Java, Scala, and different programming languages.
Snowpark for Python assessment
Snowpark for Python is to be had in public preview to all Snowflake shoppers, as of June 14, 2022. Along with the Snowpark Python API and Python Scalar Consumer Outlined Purposes (UDFs), Snowpark for Python helps the Python UDF Batch API (Vectorized UDFs), Desk Purposes (UDTFs), and Saved Procedures.
Those options blended with Anaconda integration give you the Python group of information scientists, knowledge engineers, and builders with a number of versatile programming contracts and get entry to to open supply Python applications to construct knowledge pipelines and mechanical device studying workflows at once inside Snowflake.
Snowpark for Python features a native construction revel in you’ll set up by yourself mechanical device, together with a Snowflake channel at the Conda repository. You’ll use your most well-liked Python IDEs and dev equipment and be capable to add your code to Snowflake figuring out that it’ll be appropriate.
Via the best way, Snowpark for Python is loose open supply. That’s a transformation from Snowflake’s historical past of retaining its code proprietary.
The next pattern Snowpark for Python code creates a DataFrame that aggregates guide gross sales by way of 12 months. Underneath the hood, DataFrame operations are transparently transformed into SQL queries that get driven right down to the Snowflake SQL engine.
from snowflake.snowpark import Consultation
from snowflake.snowpark.purposes import col# fetch snowflake connection data
from config import connection_parameters# construct connection to Snowflake
consultation = Consultation.builder.configs(connection_parameters).create()# use Snowpark API to combination guide gross sales by way of 12 months
booksales_df = consultation.desk("gross sales")
booksales_by_year_df = booksales_df.groupBy(12 months("sold_time_stamp")).agg([(col("qty"),"count")]).kind("rely", ascending=False)
booksales_by_year_df.display()
Getting began with Snowpark Python
Snowflake’s “getting began” educational demonstrates an end-to-end knowledge science workflow the usage of Snowpark for Python to load, blank, and get ready knowledge after which deploy the skilled type to Snowflake the usage of a Python UDF for inference. In 45 mins (nominally), it teaches:
- Tips on how to create a DataFrame that rather a lot knowledge from a degree;
- Tips on how to carry out knowledge and have engineering the usage of the Snowpark DataFrame API; and
- Tips on how to deliver a skilled mechanical device studying type into Snowflake as a UDF to attain new knowledge.
The duty is the vintage buyer churn prediction for an web provider supplier, which is an easy binary classification downside. The academic begins with a neighborhood setup section the usage of Anaconda; I put in Miniconda for that. It took longer than I anticipated to obtain and set up all of the dependencies of the Snowpark API, however that labored superb, and I admire the best way Conda environments steer clear of clashes amongst libraries and variations.
This quickstart starts with a unmarried Parquet report of uncooked knowledge and extracts, transforms, and rather a lot the related data into more than one Snowflake tables.
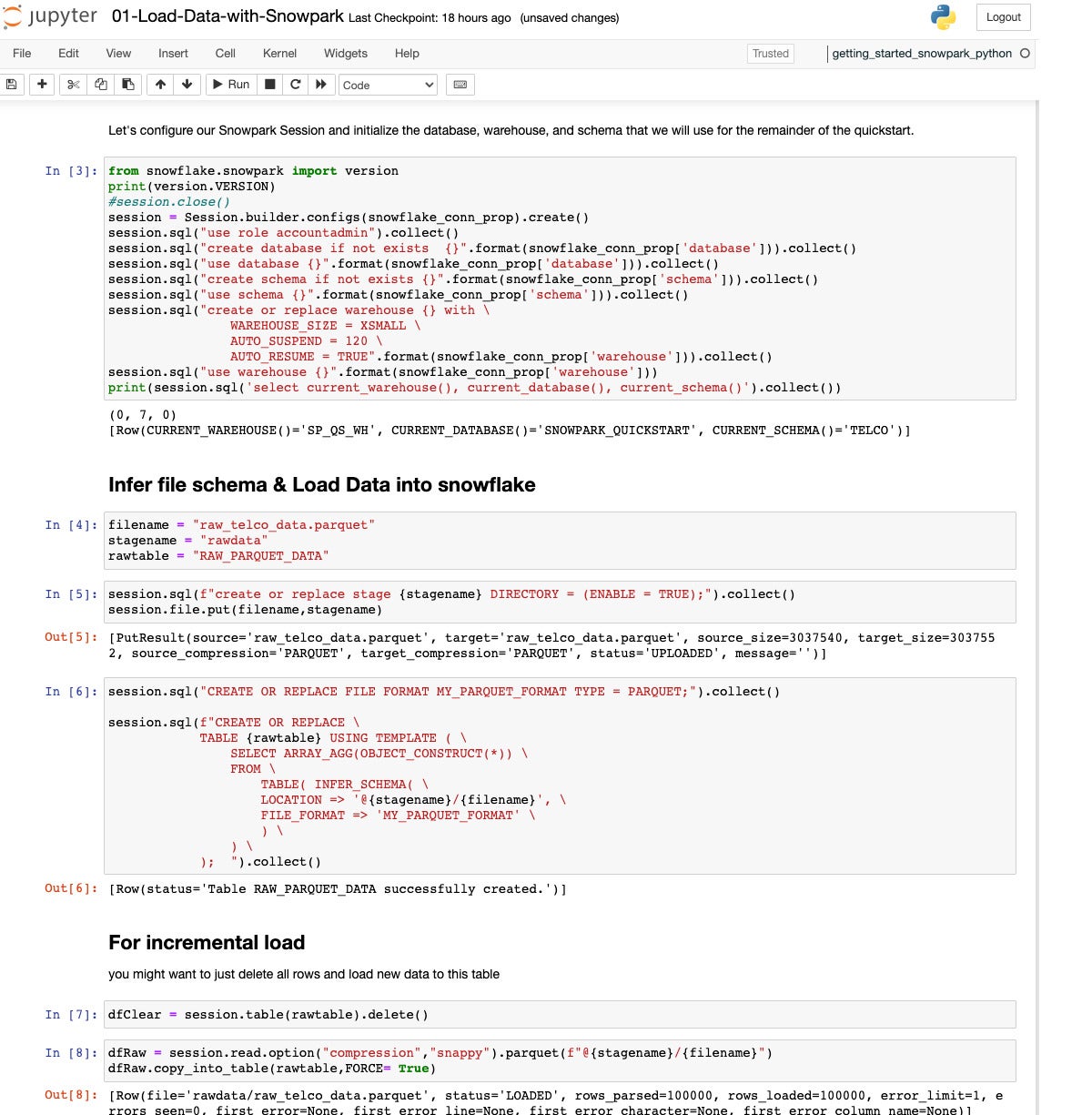 IDG
IDGWe’re having a look originally of the “Load Knowledge with Snowpark” quickstart. This can be a Python Jupyter Pocket book working on my MacBook Professional that calls out to Snowflake and makes use of the Snowpark API. Step 3 at first gave me issues, as a result of I wasn’t transparent from the documentation about the place to seek out my account ID and what sort of of it to incorporate within the account box of the config report. For long run reference, glance within the “Welcome To Snowflake!” e-mail in your account data.
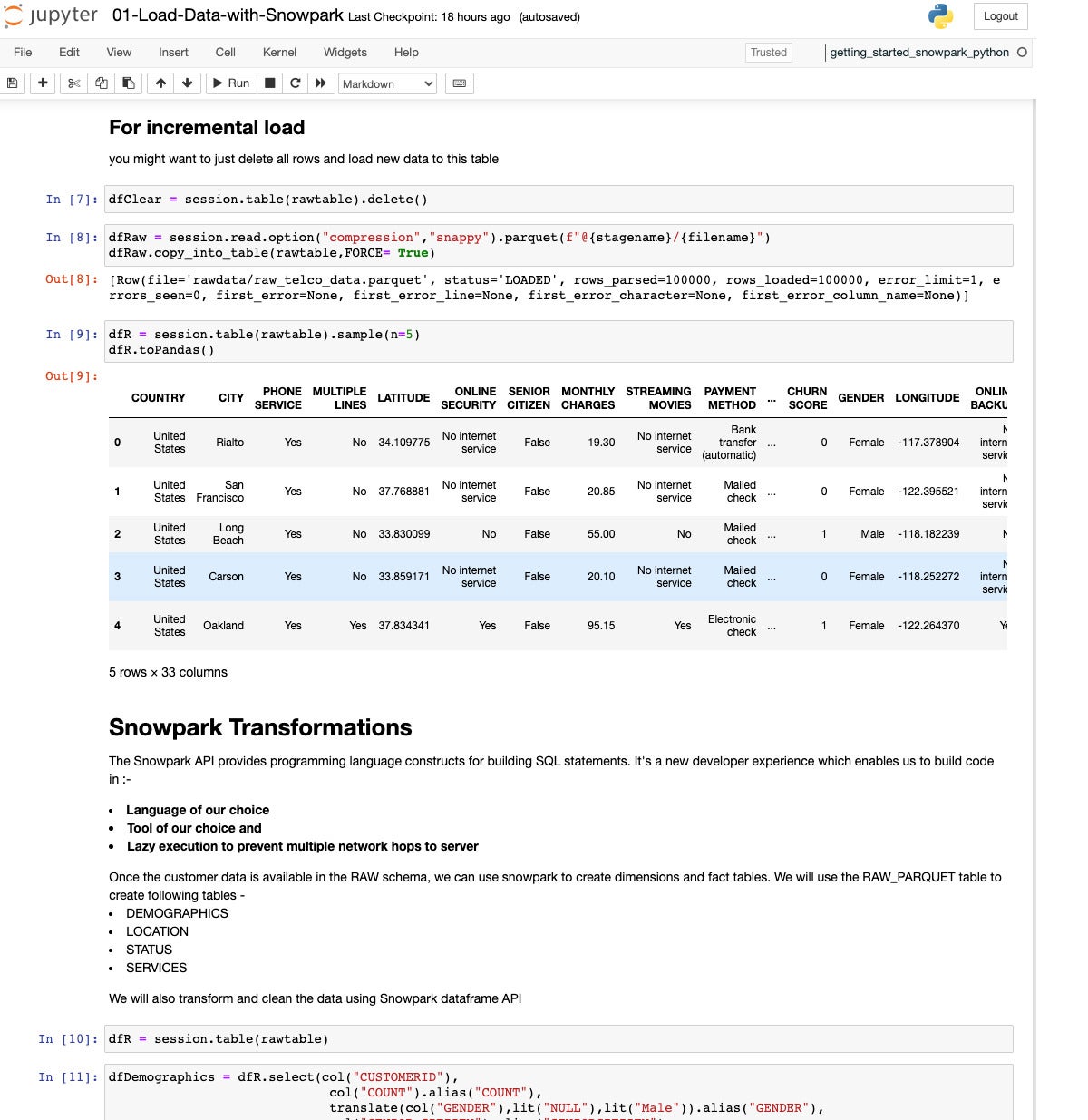 IDG
IDGRight here we’re checking the loaded desk of uncooked historic buyer knowledge and starting to arrange some transformations.
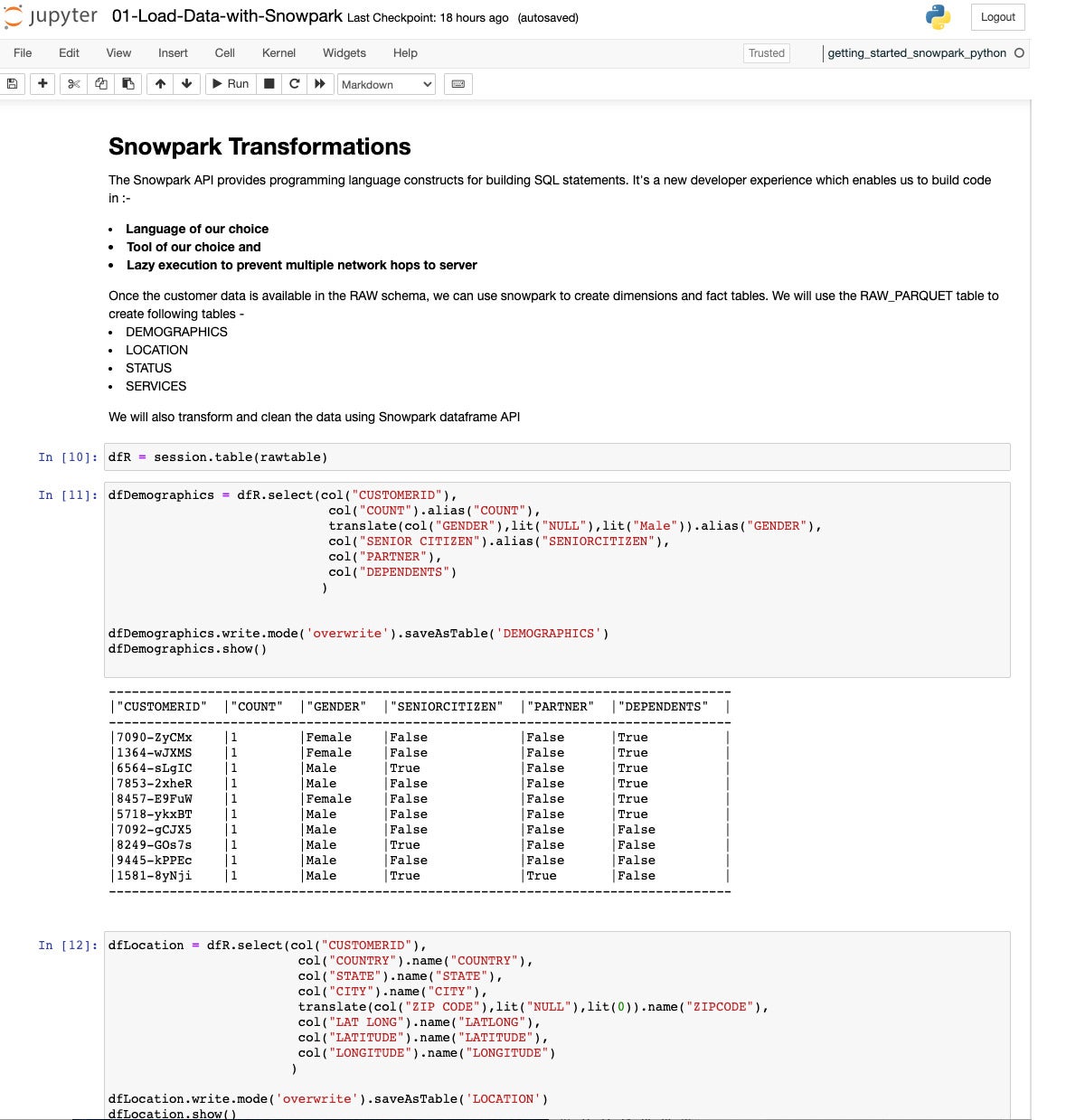 IDG
IDGRight here we’ve extracted and remodeled the demographics knowledge into its personal DataFrame and stored that as a desk.
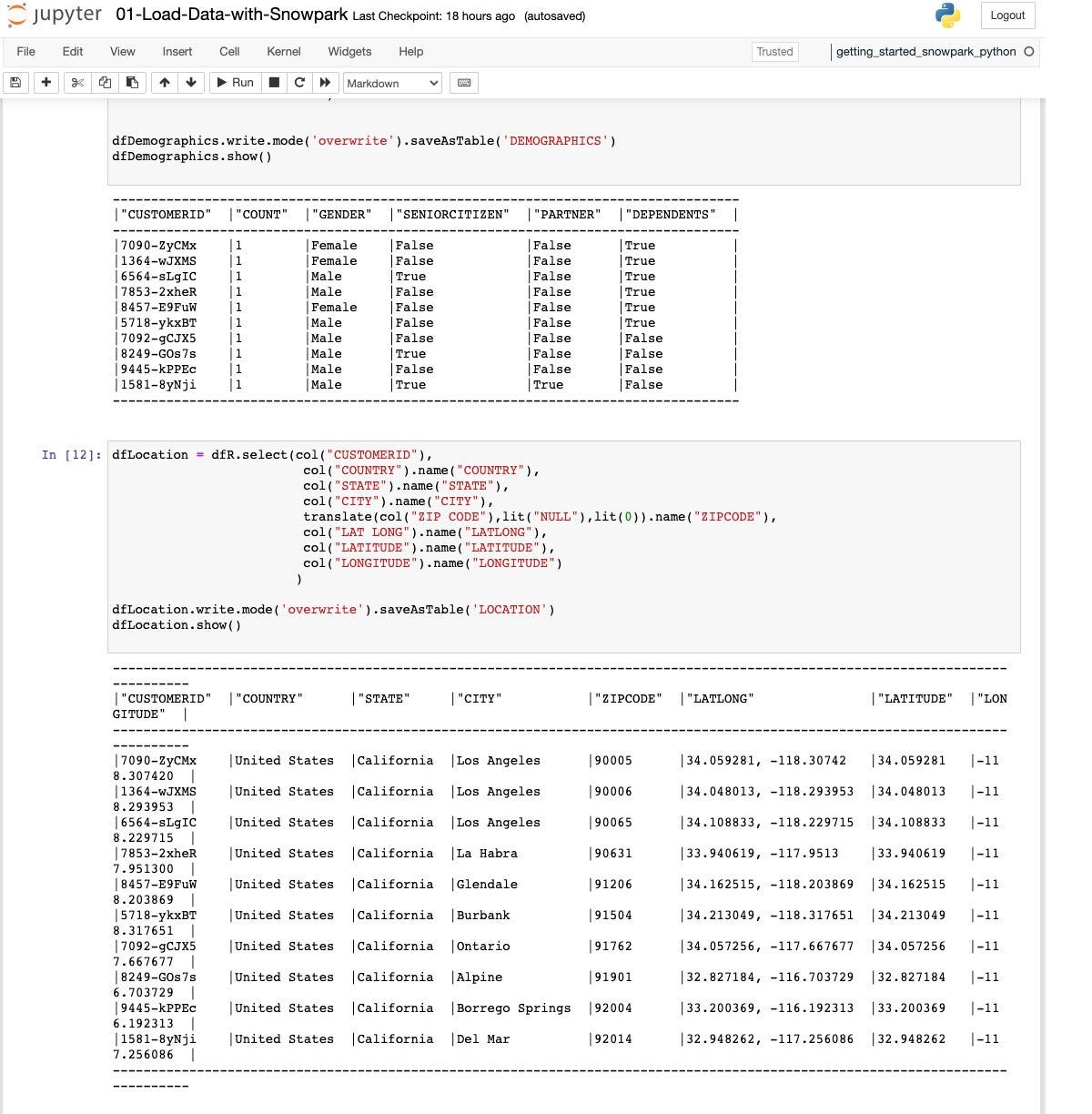 IDG
IDGIn step 12, we extract and change into the fields for a location desk. As ahead of, that is finished with a SQL question right into a DataFrame, which is then stored as a desk.
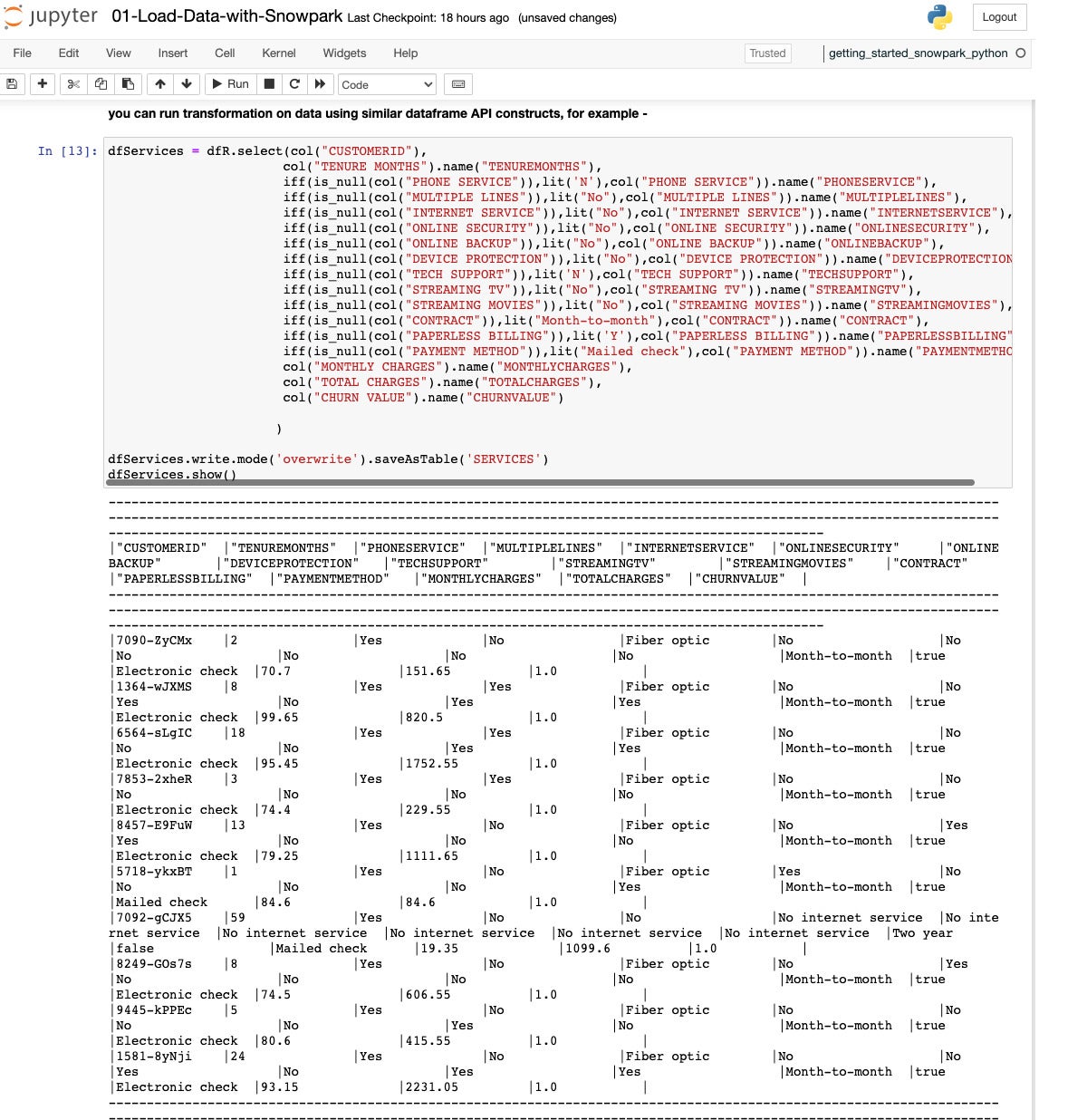 IDG
IDGRight here we extract and change into knowledge from the uncooked DataFrame right into a Services and products desk in Snowflake.
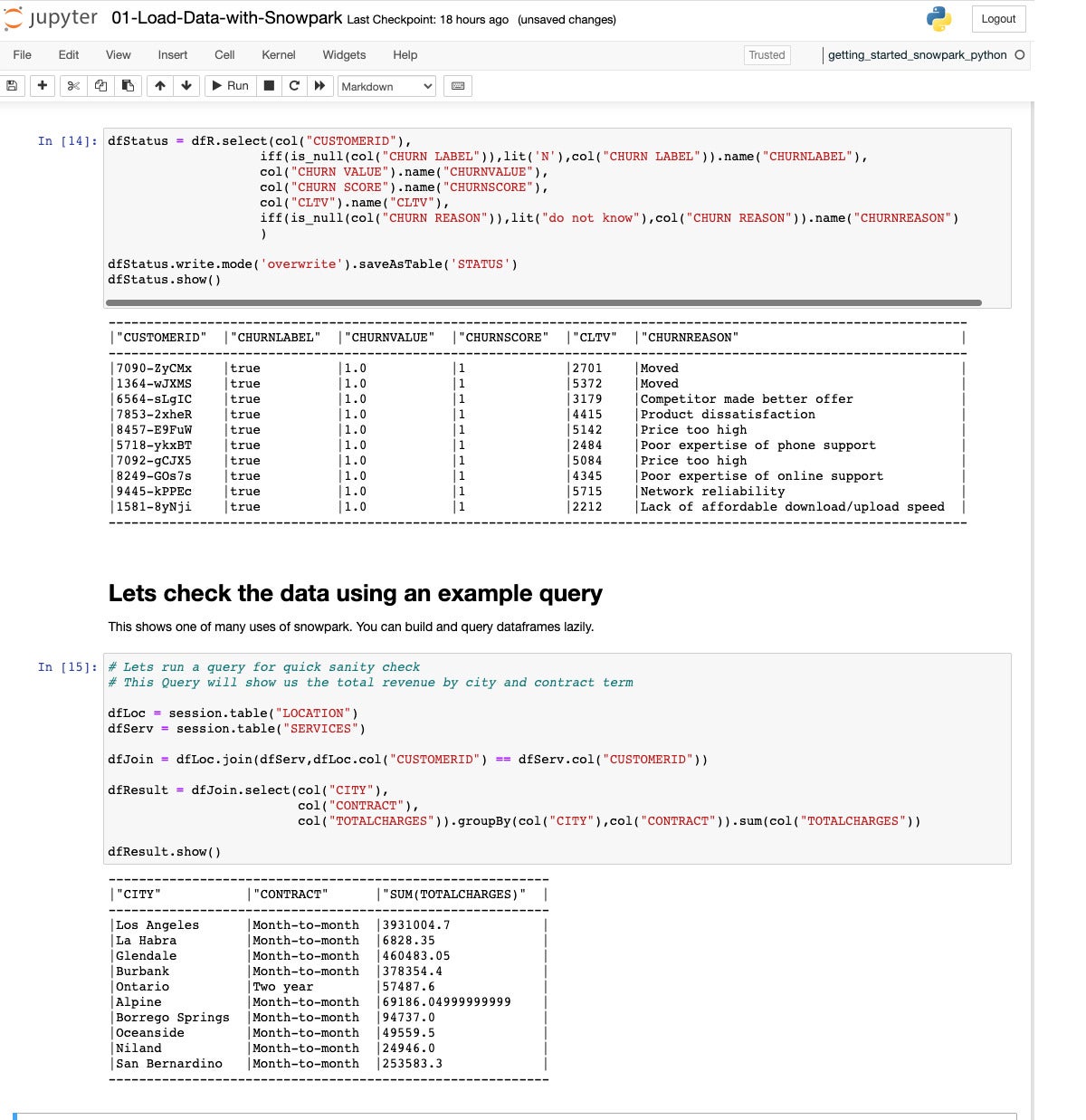 IDG
IDGSubsequent we extract, change into, and cargo the overall desk, Standing, which displays the churn standing and the cause of leaving. Then we do a snappy sanity test, becoming a member of the Location and Services and products tables right into a Sign up for DataFrame, then aggregating general fees by way of town and form of contract for a Consequence DataFrame.
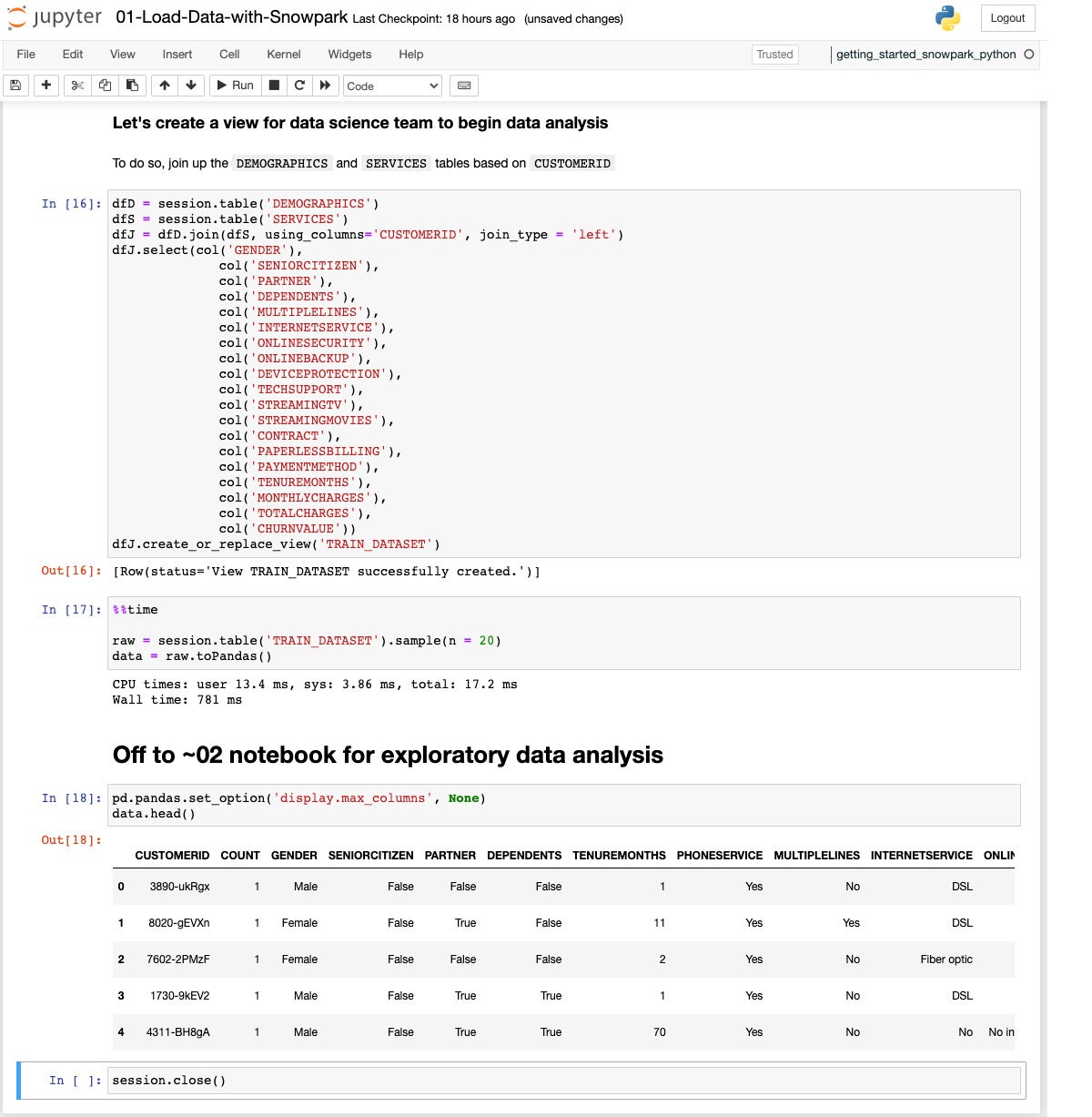 IDG
IDGOn this step we sign up for the Demographics and Services and products tables to create a TRAIN_DATASET view. We use DataFrames for intermediate steps, and use a make a selection remark at the joined DataFrame to reorder the columns.
Now that we’ve completed the ETL/knowledge engineering section, we will be able to transfer directly to the information research/knowledge science section.
 IDG
IDGThis web page introduces the research we’re about to accomplish.
 IDG
IDGWe begin by way of pulling within the Snowpark, Pandas, Scikit-learn, Matplotlib, datetime, NumPy, and Seaborn libraries, in addition to studying our configuration. Then we determine our Snowflake database consultation, pattern 10K rows from the TRAIN_DATASET view, and convert that to Pandas structure.
 IDG
IDGWe proceed with some exploratory knowledge research the usage of NumPy, Seaborn, and Pandas. We search for non-numerical variables and classify them as classes.
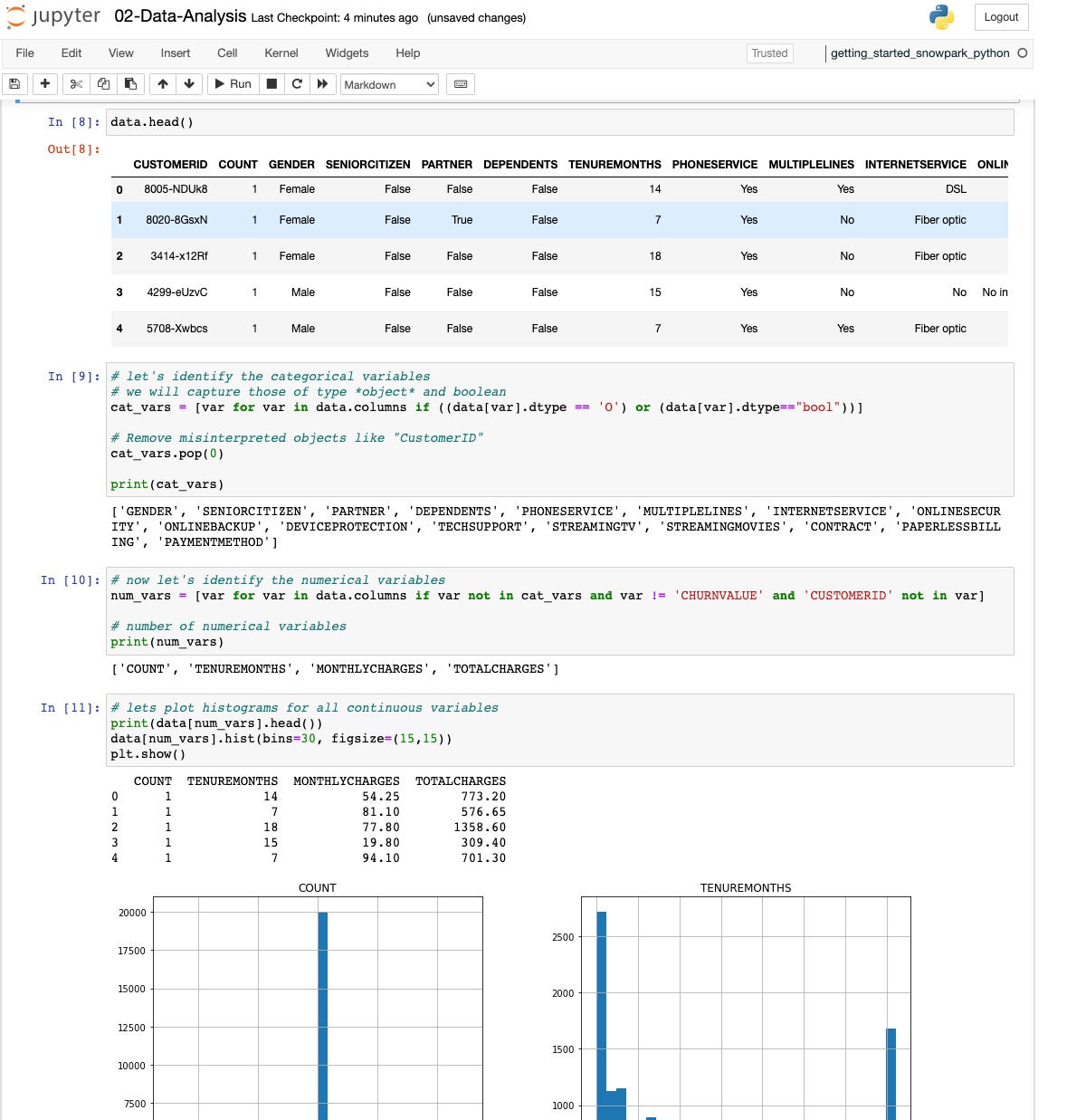 IDG
IDGAs soon as we’ve got discovered the explicit variables, then we establish the numerical variables and plot some histograms to look the distribution.
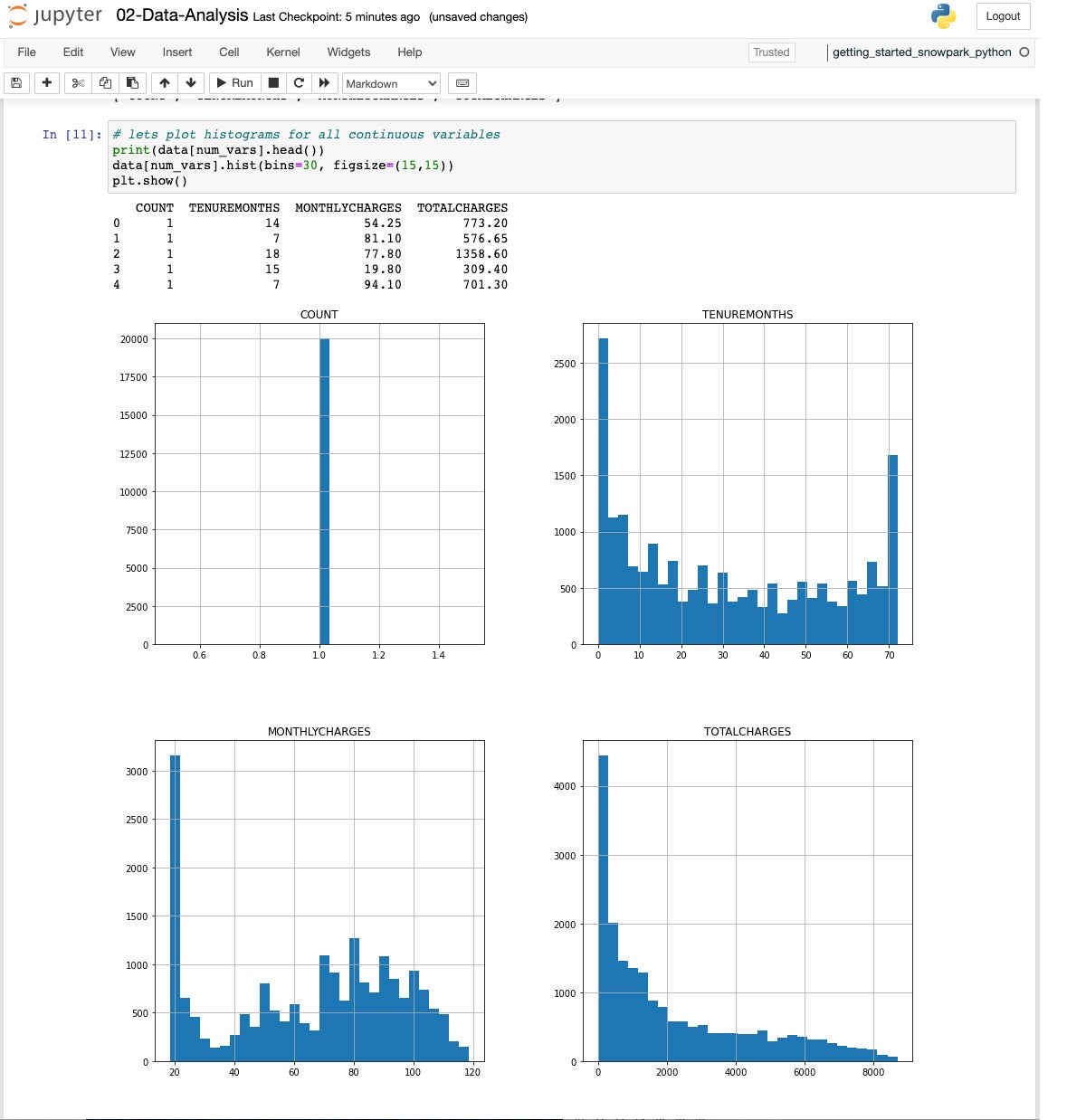 IDG
IDGAll 4 histograms.
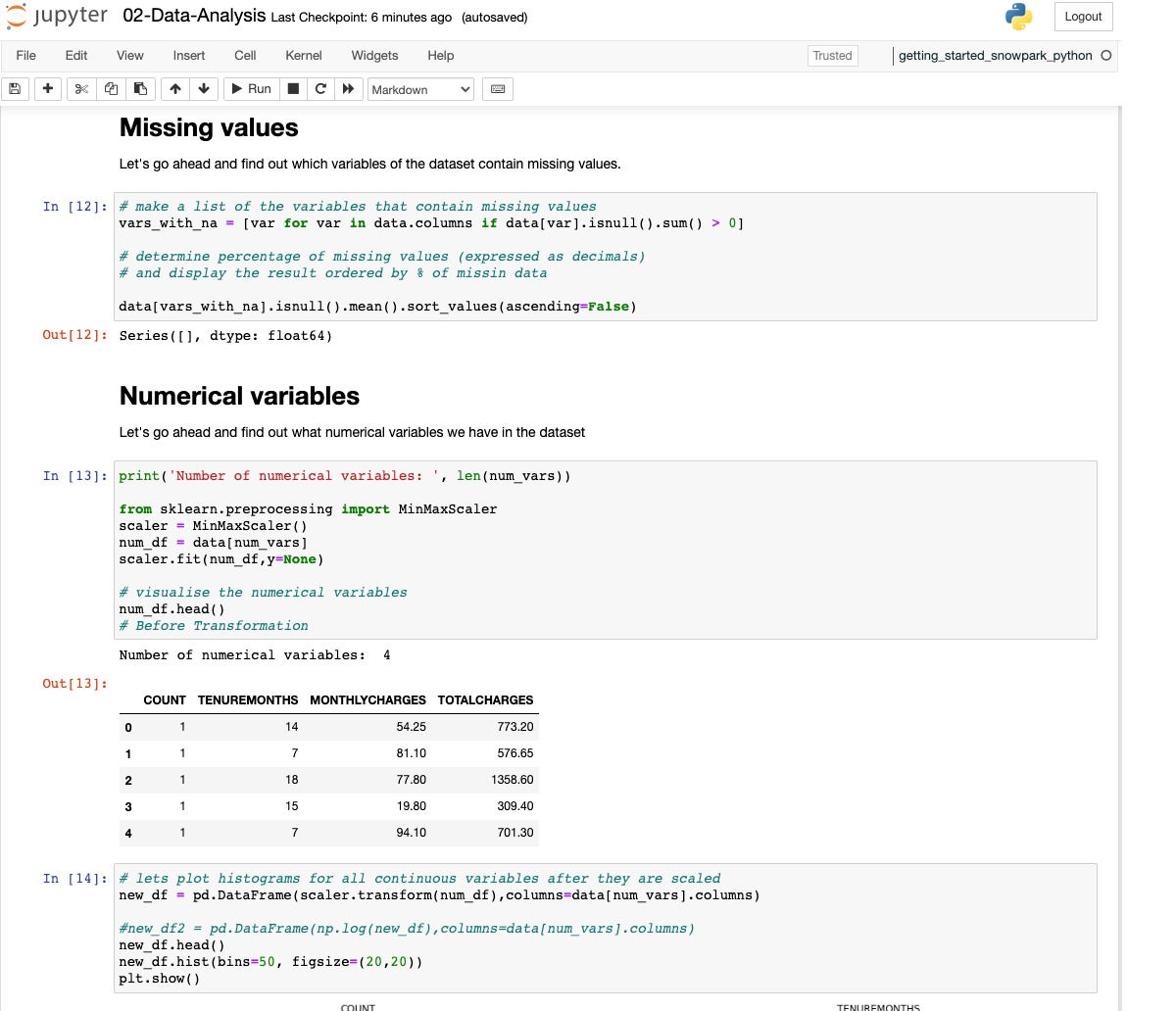 IDG
IDGGiven the collection of levels we noticed within the earlier display, we wish to scale the variables to be used in a type.
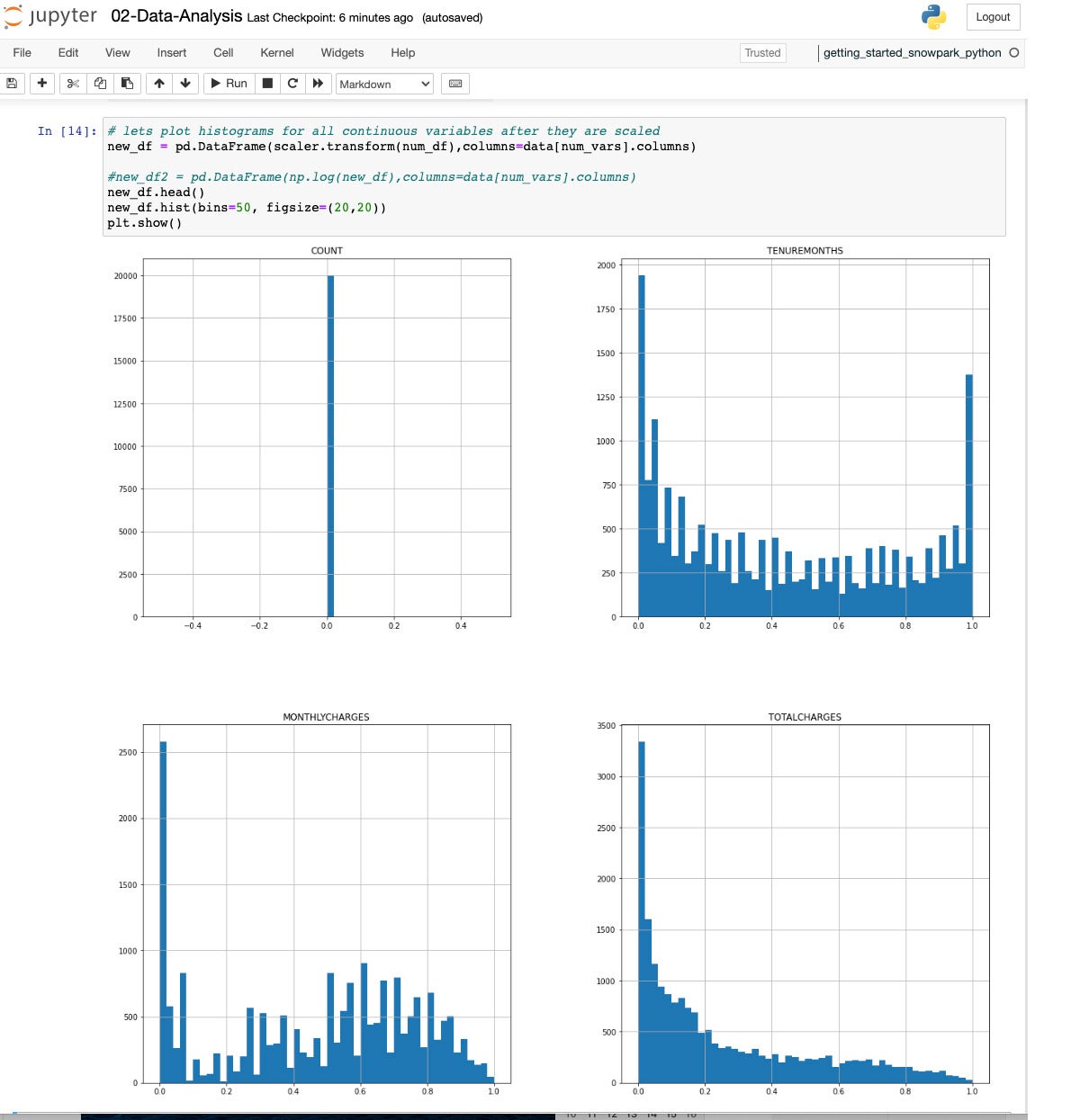 IDG
IDGHaving all of the numerical variables lie within the vary from 0 to one will lend a hand immensely after we construct a type.
 IDG
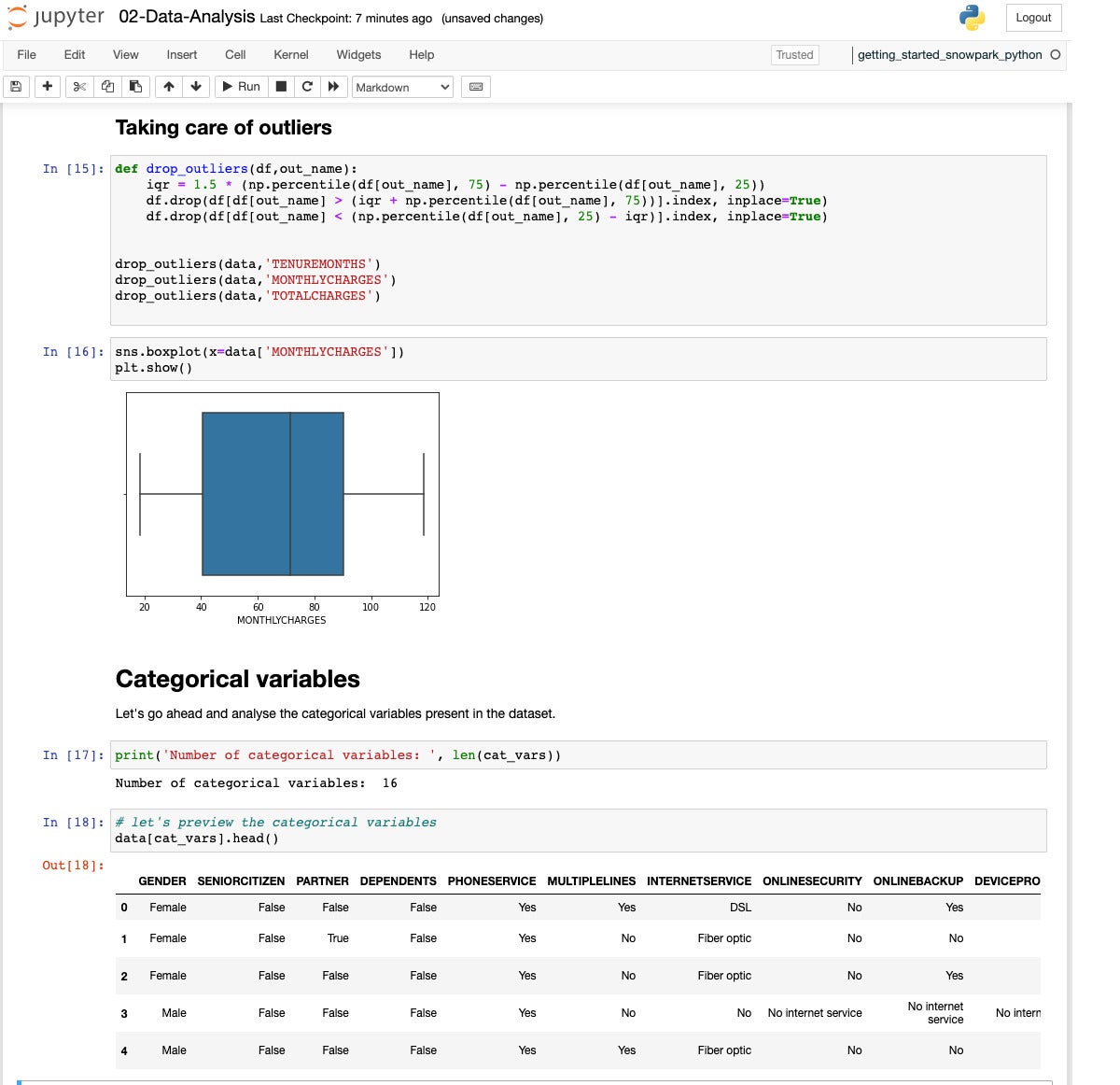
IDG3 of the numerical variables have outliers. Let’s drop them to steer clear of having them skew the type.
 IDG
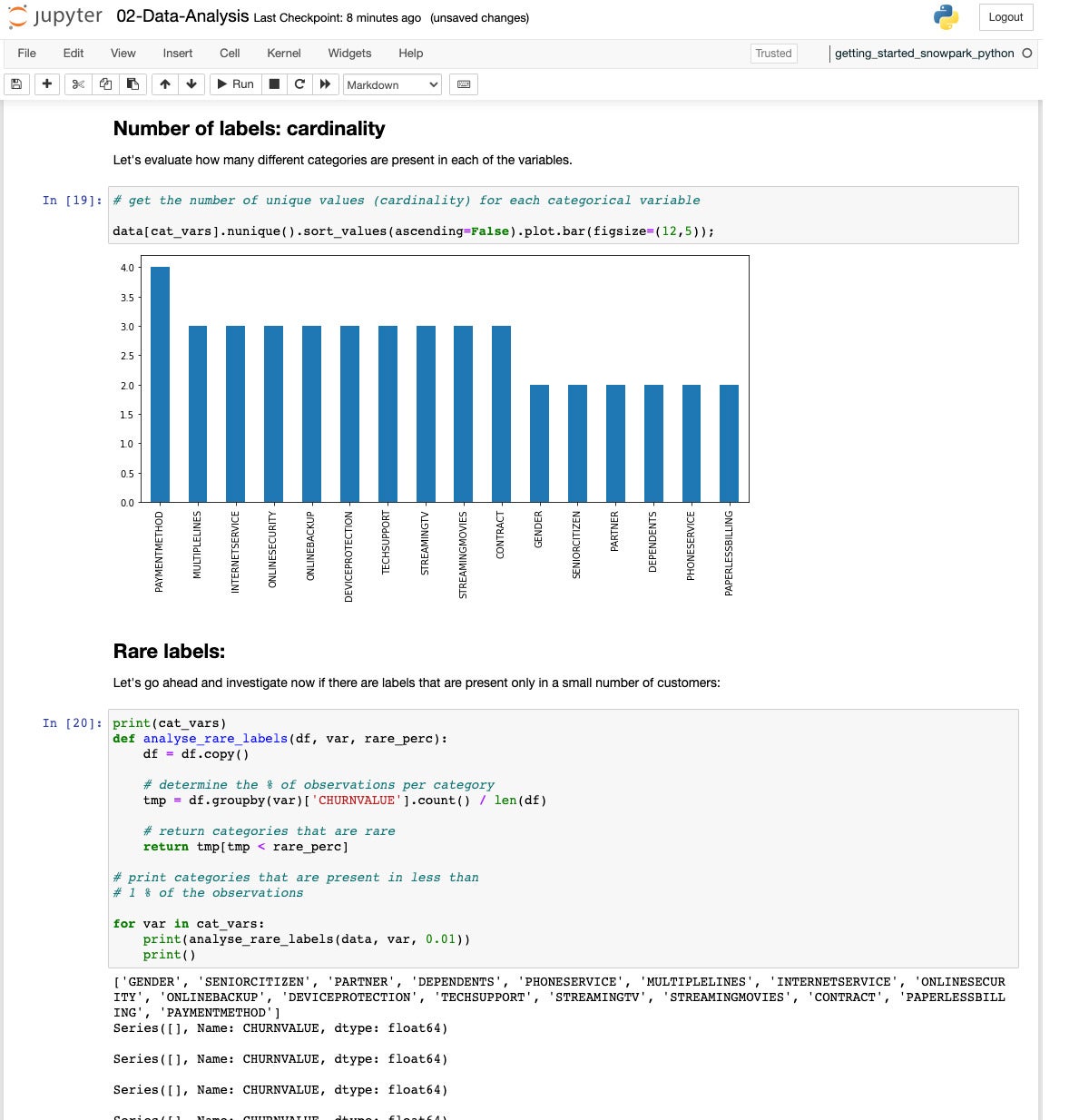
IDGIf we take a look at the cardinality of the explicit variables, we see they vary from 2 to 4 classes.
 IDG
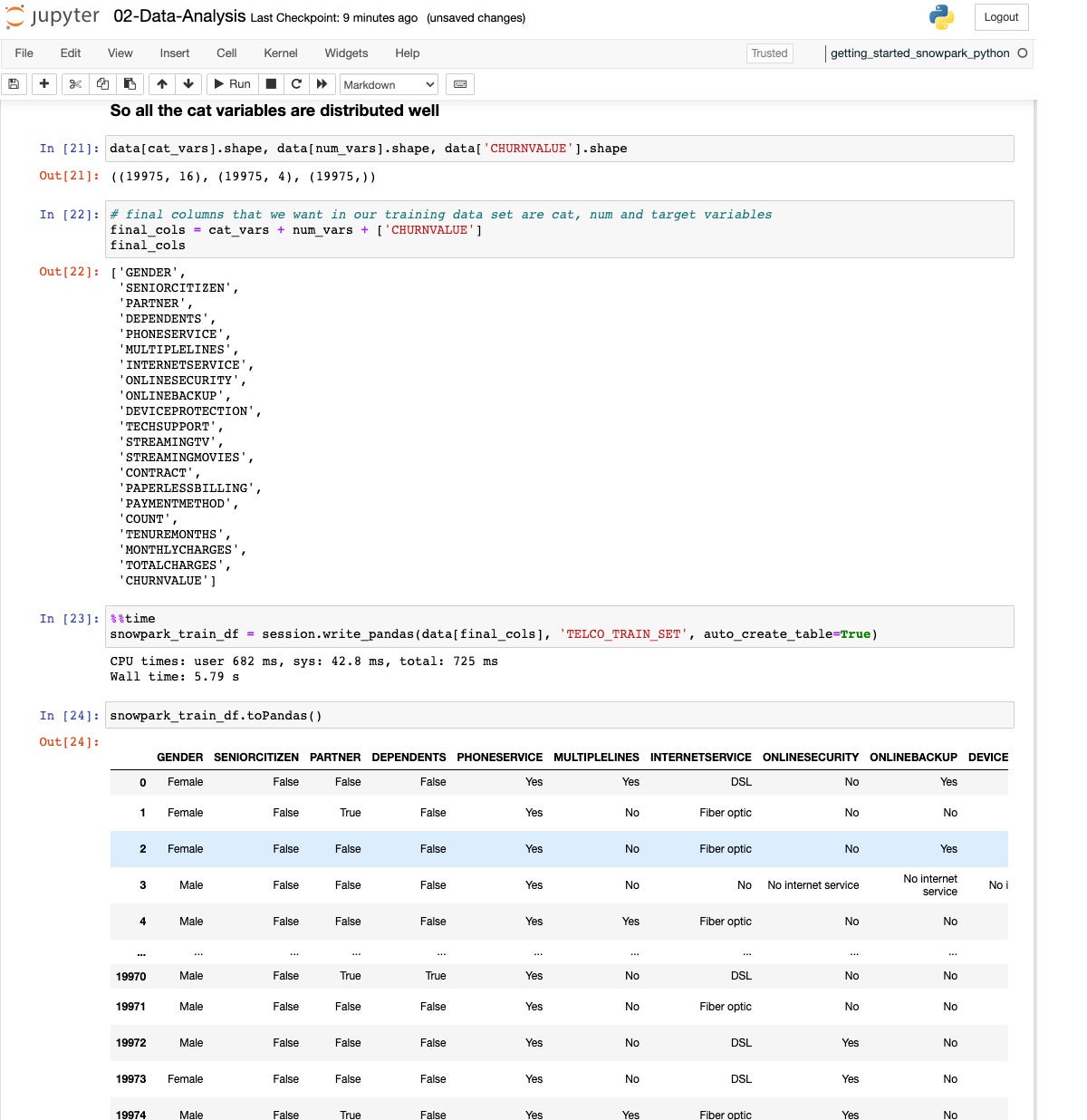
IDGWe pick out our variables and write the Pandas knowledge out to a Snowflake desk, TELCO_TRAIN_SET.
In the end we create and deploy a user-defined serve as (UDF) for prediction, the usage of extra knowledge and a greater type.
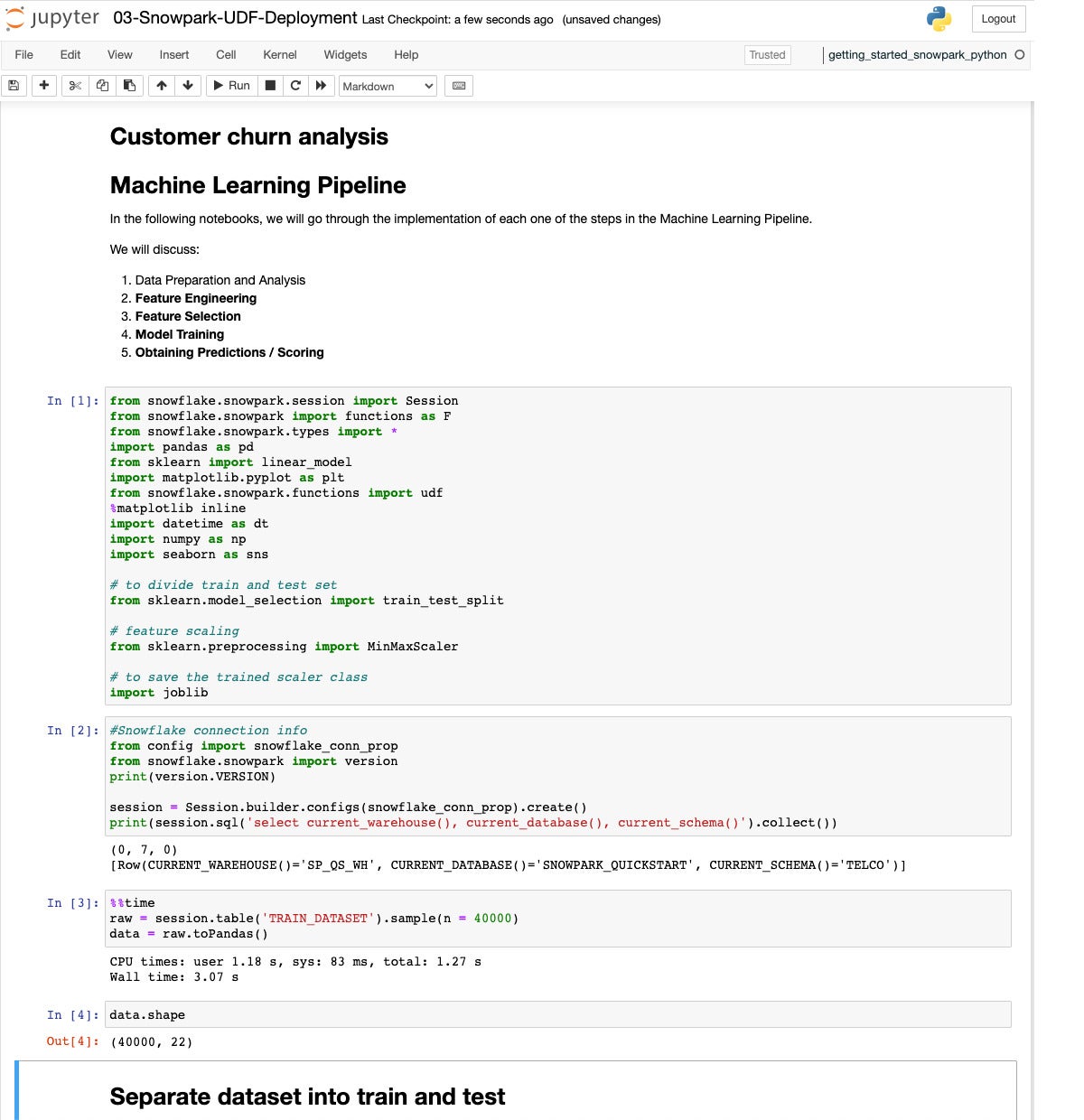 IDG
IDGNow we arrange for deploying a predictor. This time we pattern 40K values from the learning dataset.
 IDG
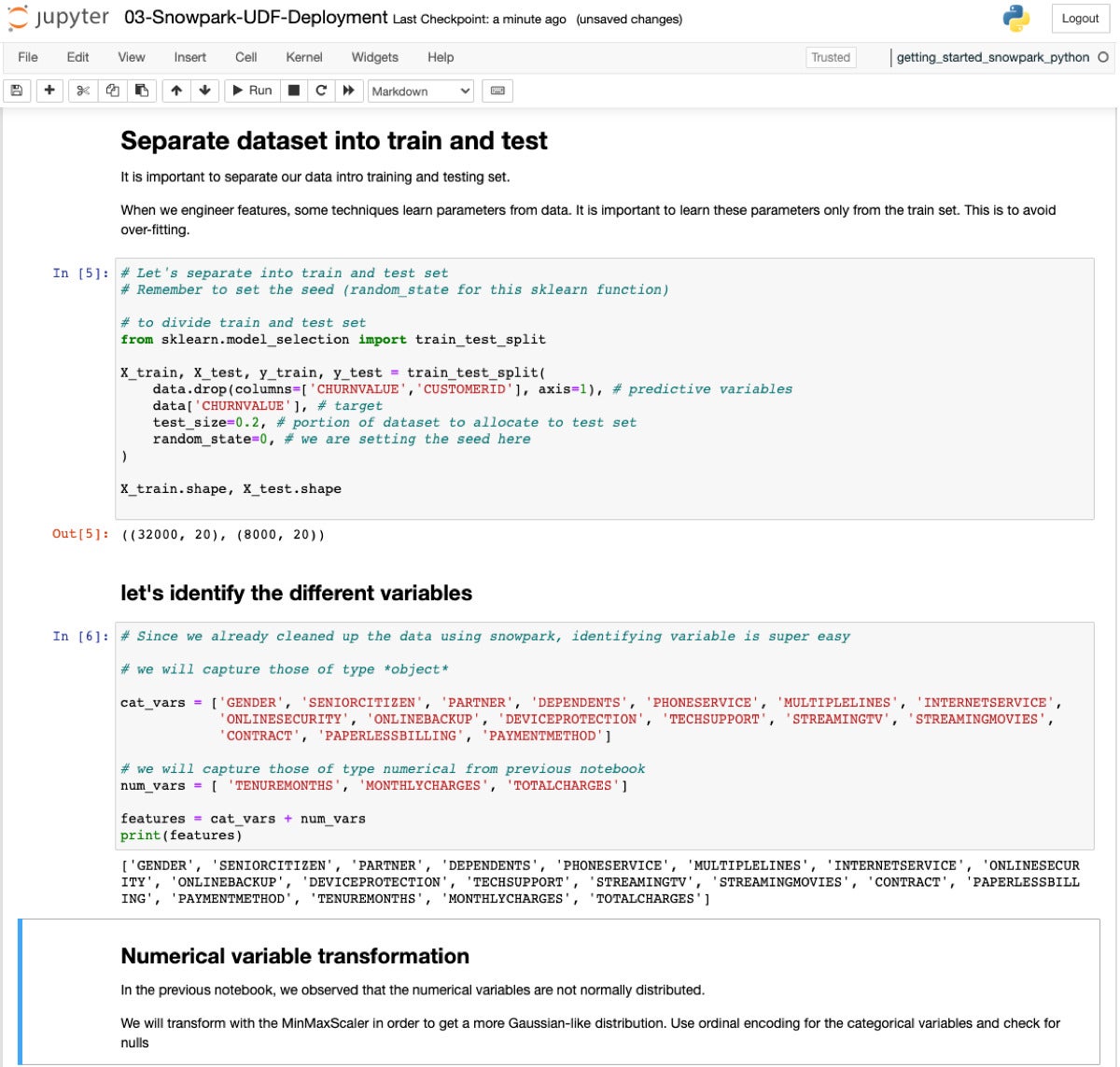
IDGNow we’re putting in place for type becoming, on our solution to deploying a predictor. Splitting the dataset 80/20 is same old stuff.
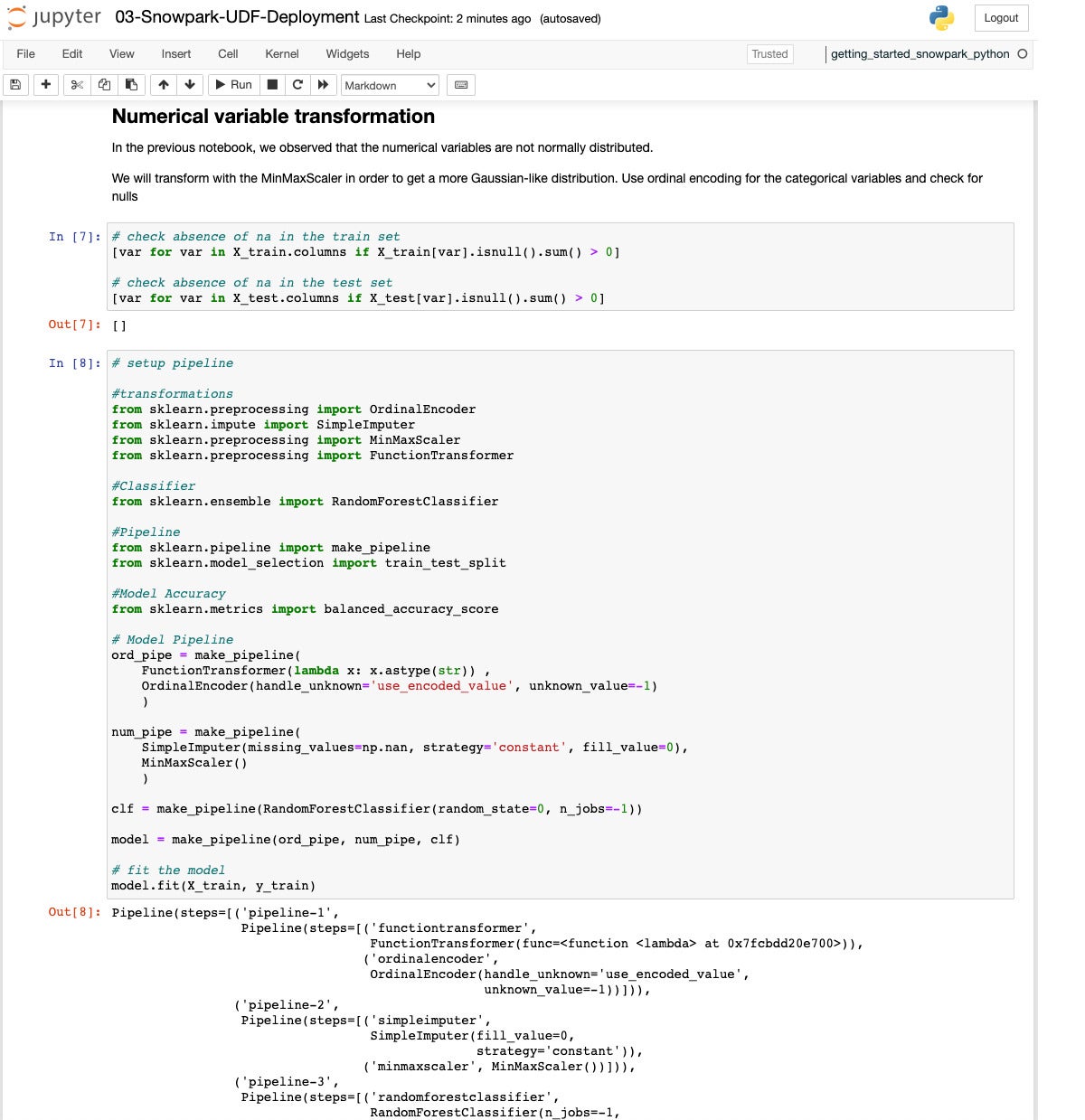 IDG
IDGThis time we’ll use a Random Woodland classifier and arrange a Scikit-learn pipeline that handles the information engineering in addition to doing the appropriate.
 IDG
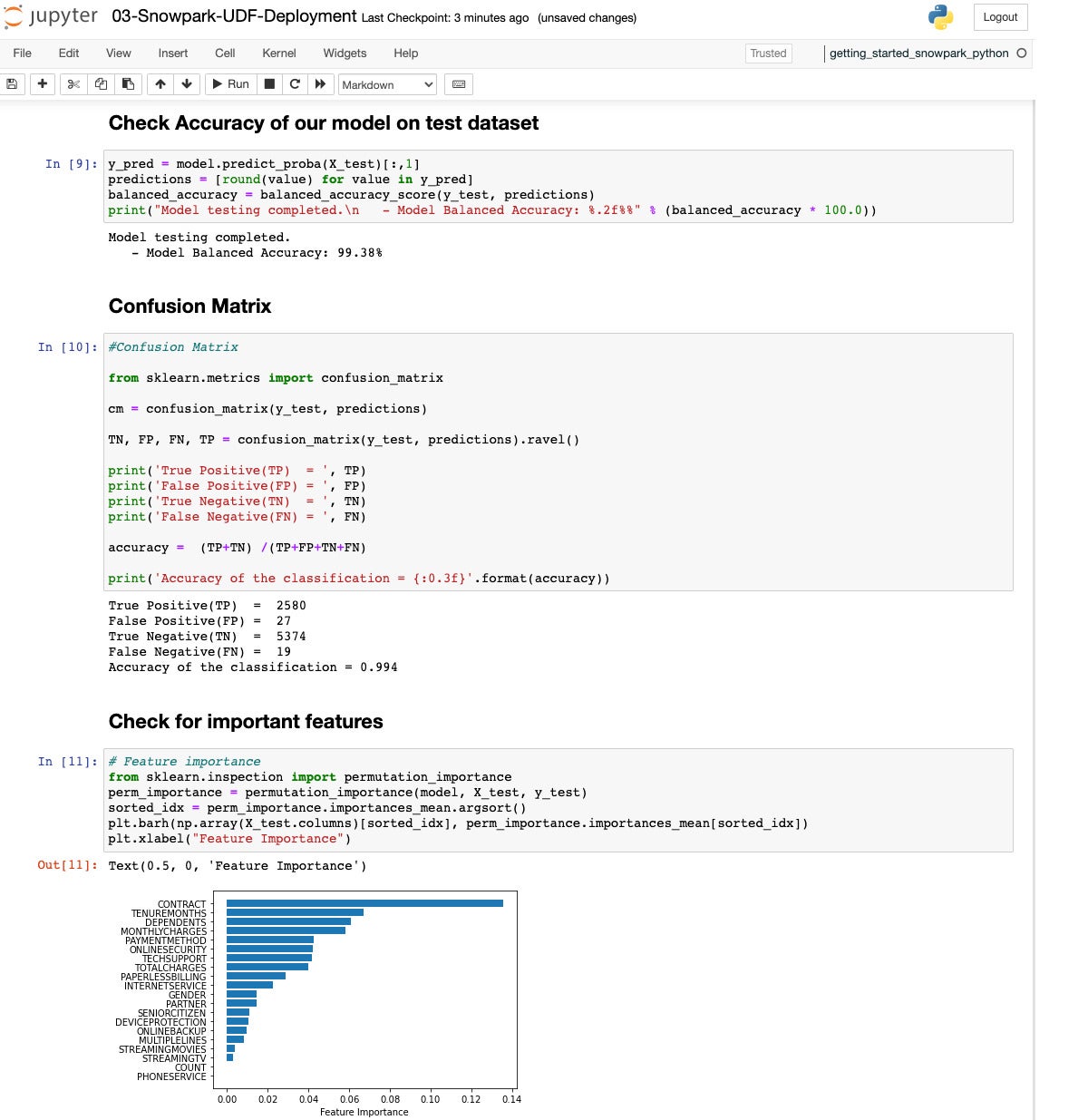
IDGLet’s see how we did. The accuracy is 99.38%, which isn’t shabby, and the confusion matrix displays reasonably few false predictions. An important function is whether or not there’s a contract, adopted by way of tenure duration and per thirty days fees.
 IDG
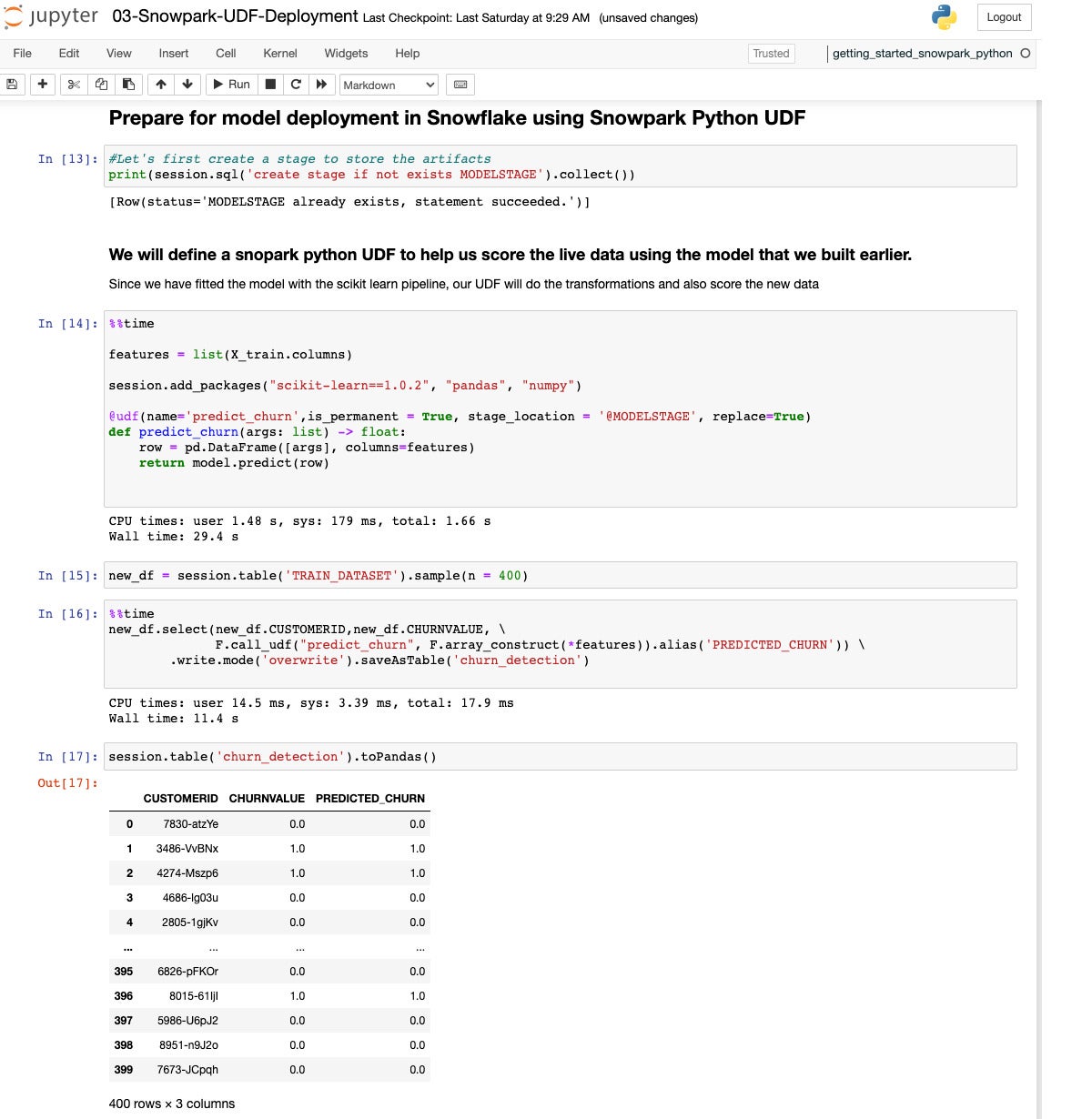
IDGNow we outline a UDF to are expecting churn and deploy it into the information warehouse.
 IDG
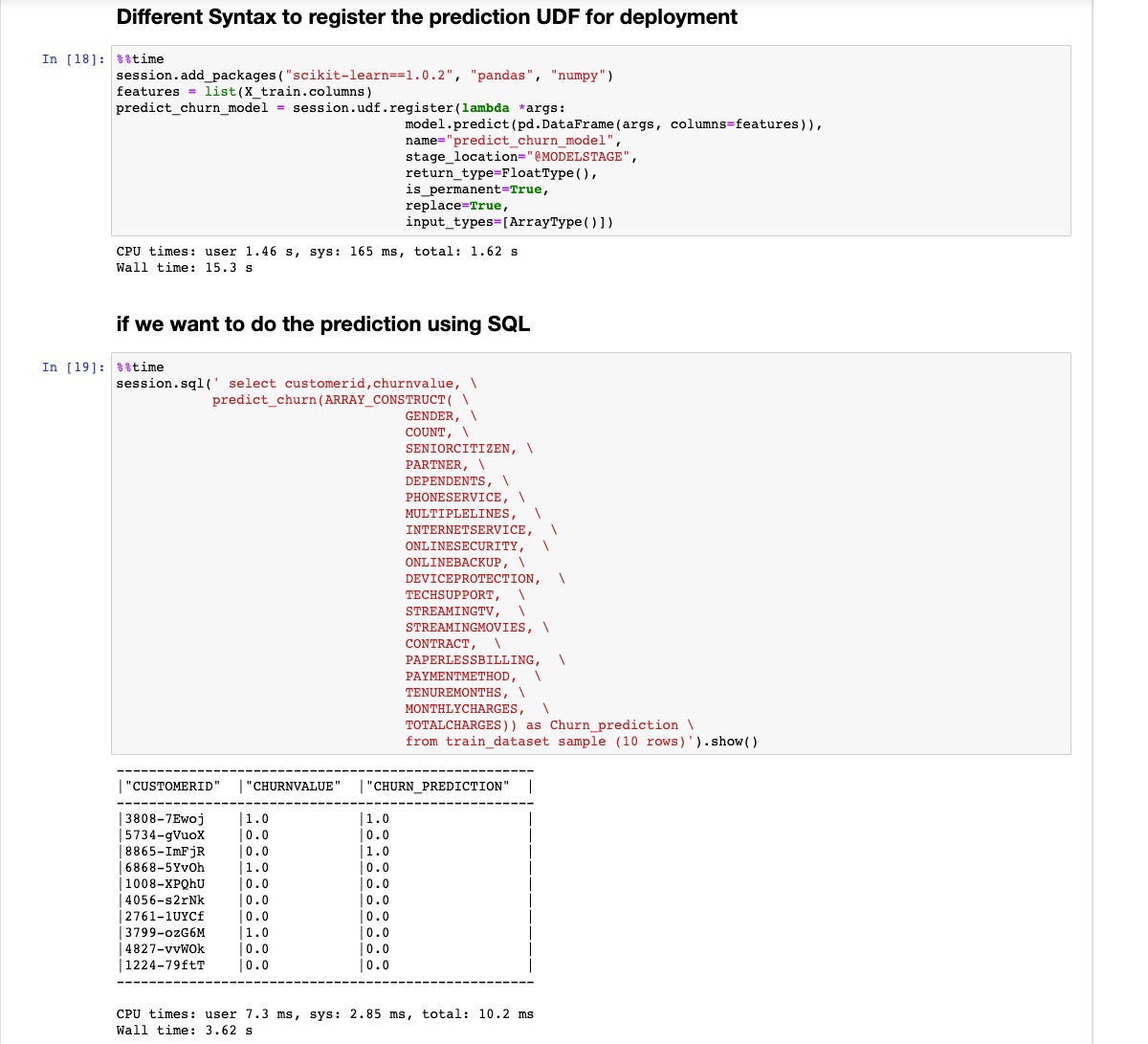
IDGStep 18 displays in a different way to check in the UDF, the usage of consultation.udf.check in() as an alternative of a make a selection remark. Step 19 displays in a different way to run the prediction serve as, incorporating it right into a SQL make a selection remark as an alternative of a DataFrame make a selection remark.
You’ll move into extra intensity by way of working Device Studying with Snowpark Python, a 300-level quickstart, which analyzes Citibike condominium knowledge and builds an orchestrated end-to-end mechanical device studying pipeline to accomplish per thirty days forecasts the usage of Snowflake, Snowpark Python, PyTorch, and Apache Airflow. It additionally presentations effects the usage of Streamlit.
Total, Snowpark for Python is excellent. Whilst I stumbled over a few issues within the quickstart, they had been resolved slightly briefly with lend a hand from Snowflake’s extensibility improve.
I really like the big variety of common Python mechanical device studying and deep studying libraries and frameworks incorporated within the Snowpark for Python set up. I really like the best way Python code working on my native mechanical device can keep an eye on Snowflake warehouses dynamically, scaling them up and down at will to keep an eye on prices and stay runtimes moderately brief. I just like the potency of doing many of the heavy lifting throughout the Snowflake warehouses the usage of Snowpark. I really like with the ability to deploy predictors as UDFs in Snowflake with out incurring the prices of deploying prediction endpoints on main cloud services and products.
Necessarily, Snowpark for Python provides knowledge engineers and information scientists a pleasing solution to do DataFrame-style programming towards the Snowflake undertaking knowledge warehouse, together with the power to arrange full-blown mechanical device studying pipelines to run on a recurrent time table.
—
Price: $2 in keeping with credit score plus $23 in keeping with TB monthly garage, same old plan, pay as you go garage. 1 credit score = 1 node*hour, billed by way of the second one. Upper point plans and on-demand garage are costlier. Knowledge switch fees are further, and range by way of cloud and area. When a digital warehouse isn’t working (i.e., when it’s set to sleep mode), it does no longer devour any Snowflake credit. Serverless options use Snowflake-managed compute assets and devour Snowflake credit when they’re used.
Platform: Amazon Internet Services and products, Microsoft Azure, Google Cloud Platform.
Copyright © 2022 IDG Communications, Inc.
Supply Via https://www.infoworld.com/article/3668629/review-snowflake-aces-python-machine-learning.html

